Combining an LLM and a Rules-based Chatbot
A rules-based chatbot allows for rapid development. Adding rules as you go, some of which can contain complex logic. Rules-based systems do not use large amounts of computation and especially don’t require GPUs, cheaper running costs and more responsive replies. As powerful as rules-based chatbots are, they also come with downsides. Creating rules is time-consuming and challenging to cover all the scenarios. The rules files quickly become quite large and cumbersome. Workarounds such as having a final catch-all rule can somewhat mitigate this.
Large language models (LLMs), on the other hand, use generative AI techniques to create a response for any input. Developers do not need to worry about building rules for every scenario, with LLMs trained on billions of documents—the technical downsides. LLMs can hallucinate or lie. The models have no concept of what is correct. Only the next words are statistically likely to follow the current text. The output may also be offensive. It is worth noting progress to avoid those responses, but no system will be 100% effective. LLMs are also more expensive to run, using GPUs and more complex computations, so it will take longer to generate a response. LLMs also come with legal risks over the data LLMs were trained on. I’m not a lawyer; I don’t play one on TV, but you should understand the legal questions when implementing a system using LLMs.
Combining both approaches offers another solution. The LLM provides a broad knowledge base with the rules-based system, adding specific knowledge and responses where required.
The example code extends the basic Chatbot from the previous post, adding a Large Language model as an extra stage. It allows both to type to play to their strengths. First, see if the input matches any of the rules. If nothing matches, pass the input to the LLM to generate a response. Giving the Chatbot a broad range of responses without making an expensive LLM call for each one.
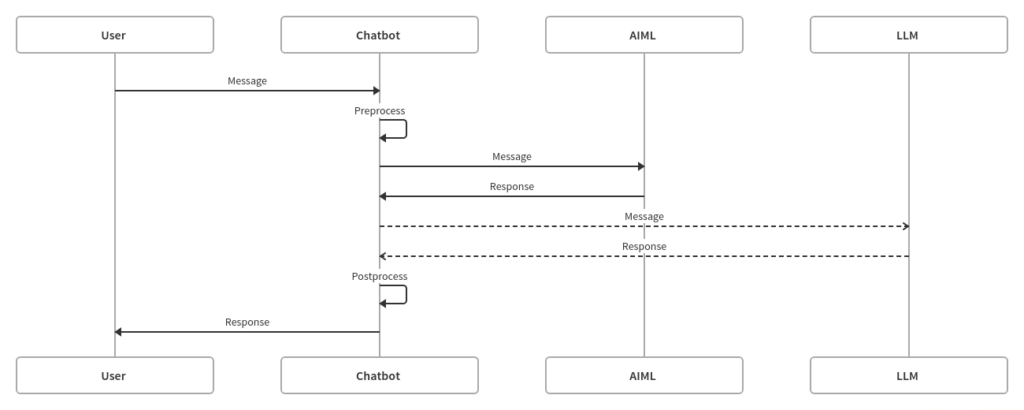
Outside of the scope of this post, the system can be further cost-optimised by implementing a cache between the LLM and Chatbot.
Also, outside of the scope of this post, producing a better response. Something that deserved its series of articles, but briefly, some approaches include starting with the simplest, passing instructions to the LLM before the input to guide the response instead of passing just the raw user input, adding Retrieval Augmented Generation (RAG) to add context based on a custom knowledge base. Finally, the costliest. Fine-tuning a custom model on your knowledge base.